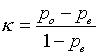
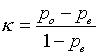
Some people find it difficult to read the returns from a ‘coding comparison query’ in NVivo. It is a confusing report. The percentage element of the report uses the total number of measurable units in the source (words in the case of a text file) and so the levels of agreement are a ratio of the total document. However, if you use the Kappa element, this is much easier to follow.
The formula means Po (portion observed) minus Pe (portion expected) over 1-Pe
0 = no agreement and the nearer you get to 1 the higher the level of agreement. If one coder codes a segment this will show as a ‘0’ because there is no agreement. However, if neither coder codes a segment, this will show as a ‘1’ because this represents total agreement (albeit negative agreement)
If both coders code a segment this will show as a number in between 0 and 1 (unless they happen to code absolutely identically which is unlikely) with 0.8 equating to the frequently used benchmark (80% being the most often used benchmark).
Drilling on these elements of the report will show you exactly what was coded and by whom. Put simply, if you concentrate on the numbers between 0 & 1 and achieve close to 0.8 on these codes; you will have achieved standard target levels of agreement.
Try running the query on your one source against all coded nodes and consider the returns between 0 & 1.
