
Avoiding the Classic Mistakes
We get a lot of queries through our website from people who are grappling with the practical application of inter-rater reliability testing in NVivo. This can be a frustrating experience as the entire coding exercise, which often involves multiple coders, sometimes has to be repeated because the test was not set up correctly in the first place. By the time people come to us for help, they have frequently made some classic mistakes already and wasted precious time to boot. This article aims to help readers identify the common pitfalls before they run their tests. It assumes the concept of inter-rater reliability testing is understood and the frustration as reported comes from not being able to conduct the test using NVivo, or from experiencing difficulty understanding and reporting on the results. There are plenty of resources out there already for getting to grips with the concept so we will not cover those in this article: http://en.wikipedia.org/wiki/Inter-rater_reliability http://en.wikipedia.org/wiki/Cohen’s_kappa
We will endeavor to demystify the process in NVivo under four headings:
· Understanding user accounts in NVivo
· Setting up a coding comparison query
· Understanding and reporting the results
· Essential “do’s and don’ts”
Understanding user accounts in NVivo
Some people do not realise that you can have user accounts in NVivo. Before conducting the test, it is essential that you set up a user account for each coder and change a default setting in NVivo which forces the user to log in every time they run NVivo. This must be done on each computer you intend to use during the test as coders may be remote. To do this go to File->Options and change the setting below to ‘Prompt for user on launch’
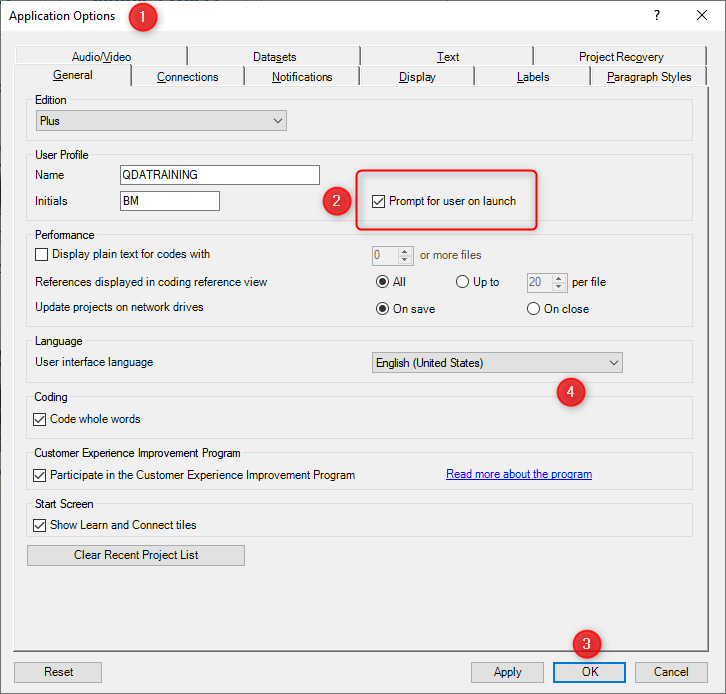
This will force coders to identify themselves to NVivo before they begin coding. Adding new users is as easy as writing in a new user name and initials. If you don’t set up user names NVivo will take the Windows logged in user name and initials by default. You are now ready to allow your coders to commence coding the same transcript. More details here: http://help-nv10.qsrinternational.com/desktop/procedures/manage_users_in_a_standalone_project.htm
Setting up a coding comparison query
In this example, we will use the standard tutorial project preloaded with NVivo so all readers automatically have a copy of this query to play with. Go to Queries and right click on the query called “Coding comparison of Wanda to Effie and Henry for Thomas interview”. Select query properties and click on the ‘Coding Comparison’ tab in the dialogue box. You will see how easy it is to set up these queries:
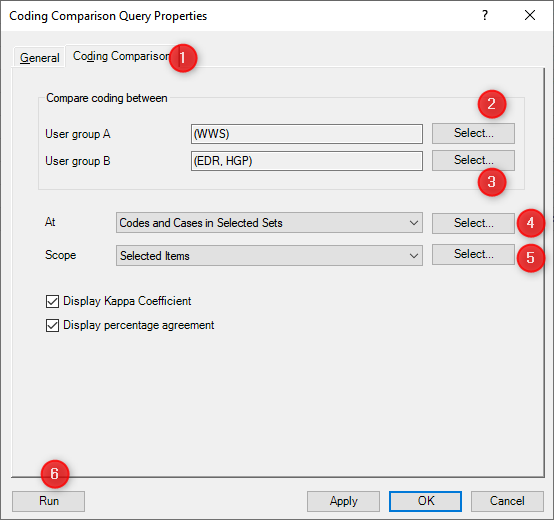
Keep the query simple to start with so you can understand the results more easily. Perhaps just two coders, one transcript and a reasonably small number of nodes. You are now ready to run the test and analyse the results. More details on setting up your query may be found here: https://help-nv.qsrinternational.com/12/win/v12.1.98-d3ea61/Content/queries/coding-comparison-query.htm?Highlight=coding%20comparison%20queryhttp://help-nv10.qsrinternational.com/desktop/procedures/run_a_coding_comparison_query.htm
Understanding and reporting the results
The query results report by displaying both ‘Percentage Agreement’ and ‘Kappa Coefficient’. This can be confusing because they are not using the same logic to report. You do have the option in the dialogue box to choose one and/or the other. The query result looks like this:

Kappa scores between zero and one depending on levels of agreement/disagreement while the percentage report shows some more detail. For me, the best part of this query result is the fact that you can drill down on any line to get a more visual representation of the specifics behind levels of agreement/disagreement. If you double click on the first line of the query result this is what you will see:
The illustration above shows where the coders agreed/disagreed in relation to the source content coded. However, by clicking on an individual coder’s stripe, I can see exactly what was coded by each coder as NVivo will highlight the exact text coded by that person. In addition, if I switch on the coding sub-stripes to compare what nodes they coded this content to, I will get a more holistic view of agreement levels. You can do this by right clicking on the coder’s stripe and selecting ‘Show Sub-Stripes->More Sub-Stripes. Using this option, I can filter the coding stripes to see all or some of the nodes each coder coded that segment to.
Export your query results to Excel and insert an average cell formula to see how agreement levels compare across Thomas’s entire transcript:
![]()
This exercise gives us an average Kappa score of 0.55 across the entire transcript or 0.69 if the one area of total disagreement is excluded
Essential “do’s and don’ts”
Learning from your mistakes may not be a great idea for this particular query as your coders may get less cooperative if you have to ask them to repeat the coding should the query fail due to not being set up correctly. So I have put together some common errors and omissions that we have encountered in our training and support work.
Do
- Change the default setting to force users to log in.
- Setup your user accounts for each coder.
- Conduct the testing as early as possible in the life of the project so as to align thinking. Especially if your coders are going to work remotely.
- Copy the project file to participating coders when using stand-alone projects.
- Keep the test in manageable proportions.
- Import project files from remote coders (take backups first in case anything goes wrong).
- Check for duplicate users after import and merge as may be necessary (this can happen if coders are inconsistent in how they log in. I might log in as ‘BM’ today and ‘B.M.’ tomorrow).
- Discuss results and retest if necessary.
Don’t
- Import the same source file into two separate projects. They will not merge when you merge your NVivo project files. Instead, import the file into one project and copy the NVivo project file to the second coder.
- Ask a coder to participate if their version of NVivo is later than yours. They will be able to open your file but as NVivo is not backward compatible you will not be able to import their work without upgrading the software.
- Ask a coder to participate if your own coding processes are quite advanced. You will have changed your thinking several times through coding and re-coding the data so you will likely get a poor result. Ask the coder to code against your initial codes.
- Running a coding comparison query using multiple transcripts, coders and nodes will result in a very big report which might be difficult to make sense of. Breaking the query up to compare sub-sets will make interpreting and reporting of results much easier.
- Edit any sources during the coding test as this will also cause duplication of sources on import and the test will not work. Should this happen, you will have to repeat the whole process.
Watch a video to see how it’s done:
![]() Ben Meehan is a full-time Lumivero certified independent trainer and consultant for computer aided qualitative data analysis systems (CAQDAS) for the past 23 years. His company, QDATRAINING PLC is based in Ireland. He works primarily in Ireland, the UK, France & Germany, Africa and the East Coast of the USA.
Ben Meehan is a full-time Lumivero certified independent trainer and consultant for computer aided qualitative data analysis systems (CAQDAS) for the past 23 years. His company, QDATRAINING PLC is based in Ireland. He works primarily in Ireland, the UK, France & Germany, Africa and the East Coast of the USA. ![]()
