Welcome › Forums › Forums › Getting Help with Nvivo – Scroll to end to post a question › Catalogue system for organizing codes
Tagged: NVivo Catalogue Coding System
- This topic has 4 replies, 2 voices, and was last updated 12 months ago by
Calvh.
-
AuthorPosts
-
23rd July 2025 at 3:43 pm #16291
Calvh
ParticipantThank you for the video on code management (https://qdatraining.com/nvivo-qualitative-data-analysis-coding-structure-managing-codes/)
Starting 0:52 of the first video, there is discussion of the catalogue coding system. I recognize the advantages of such a system. It makes the coding structure more manageable and allows more flexibility in how one can query their data.
But I’m also wondering about the disadvantages to such an approach. For example, instead of more direct codes (e.g. “Fishing, negative attitudes”) codes become fragmented and need to be joined via matrix intersection queries (“Fishing” + “Negative attitudes”).
It seems this “fragmentation” disadvantage can be even more cumbersome in longitudinal designs with multiple timepoints and between group comparisons. Codes will first need to be joined via an intersection query before they can be explored longitudinally and between groups using crosstabs.
Can you please comment on potential disadvantages of the catalogue system, especially in the context of longitudinal designs, and how one might overcome such disadvantages?
This matter is hardly discussed in textbooks or online resources, so I think it is a worthwhile topic.
Thanks in advance, and thank you also for the many instructional videos offered freely.
-
This topic was modified 1 year ago by
Calvh. Reason: minor typo
23rd July 2025 at 4:53 pm #16294QDATRAINING_Admin
KeymasterHi Calvin,
Let me address both parts of your question. First, should you be creating ‘virus’ codes under each theme, code or concept coded for? You point to ‘Fragmentation’ as the downside of universally coding against themes and sentiment; this is a bad idea for two reasons beyond breaking the rules of indexing by doing so. First: it is unnecessary because clicking into cells in a matrix (which gives you a more strategic view across multiple codes) will open the data behind the cell so not only can you see patterns in the data, but you can drill down immediately and see the qualitive comments behind the pattern, also revealing which positive or negative comments pertain to which code. Second: If you save the results of a matrix and copy and paste it into a coding folder you will see the matrix results in code format. In other words, you will see each code with ‘virus’ codes under each one exactly as you have described. If you do this, I advise you to create a separate folder for these matrices generated codes to preserve the integrity of your original code. It is also far easier to code to a single sentiment code at the same time as coding to a theme than it is to plough through all your sentiment child codes under multiple themes to find the right one. This is much more cumbersome to do. Using this method, you get the best of both worlds plus the strategic view in the matrix table.
With regard to the longitudinal part of your question, this can be easily dealt with by applying an additional filter to your matrix. If you make sets out of your timepoints and use the ‘Selected items; options in the matrix you can filter the matrix results by time points. Alternatively, you could use a three-dimensional matrix using the steps outlined above to first create a set of codes x theme Vs sentiment, save the results as codes and put the new codes into a matrix against the sets of timepoints. This will give you a three-way matrix dividing each code by sentiment and then by timepoint leaving you with a matrix showing Codes X Sentiment X Timepoints which would look something like this:
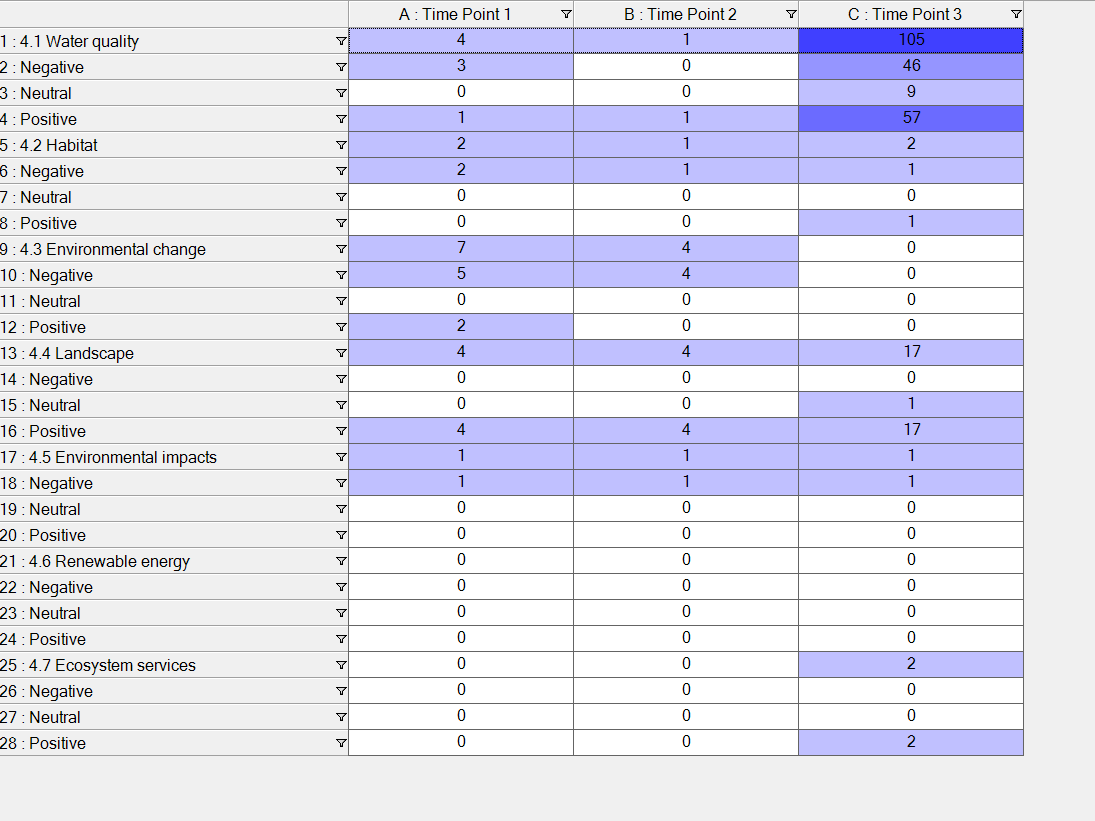 24th July 2025 at 3:02 am #16295Participant
24th July 2025 at 3:02 am #16295ParticipantThank you Ben, for your very detailed response.
I was on the fence about switching to the catalogue system because although a viral pattern was beginning to emerge in my coding structure, it wasn’t severe enough (yet) to make the switch necessary. Your explanations and detailed instructions provide the assurance I was seeking, and I’ve made the switch.
If you happen to know any resources/texts that offer additional strategies for dealing with this matter in designs with ≥2 time points and/or ≥2 comparison groups, I’d be grateful for any recommendations. If none come to mind, what you’ve provided here is already extremely helpful and gives me plenty to work with. My sincere thanks once again for your generous response.
With thanks,
Calvin24th July 2025 at 4:01 pm #16297KeymasterHi Calvin,
The reason you find it difficult to come across reliable literature on coding strategies in tools like NVivo is that most popular authors of data analysis methods wrote their books and papers for manual analysis (IPA, Thematic Analysis, discourse analysis, grounded theory and so forth). As a result, they fundamentally don’t know how their guidelines can be applied in a database environment, so it’s never included. Principles such as ‘virus codes’ and tools like matrices are alien if you designed your method around manual coding protocols. Of course, these principles are sound and can easily be applied in a database environment, but it does require an understanding of the tool which may not been in the consciousness of authors at that time or based on their personal knowledge of technologies when they wrote their books.
There are lots of videos and tutorials on tools such as matrices, crosstab, compound queries etc but I suppose the researcher has to know which tools apply to which coding principle to be able to make sense of them. NVivo trainers will include these inculcate links between academic principles and technologies but there not much in literature. There is a book written by Pat Bazeley and Kristi Jackson which might be worth looking up because both authors are NVivo trainers but also academics so there is a good fit between the technology and academia. There is a companion website as well. It was written using NVivo 12 which was the newest version at that time, but the principles are just as relevant in any of the later releases.
Companion Website: https://study.sagepub.com/bazeleynvivo
Bazeley, P., & Jackson, K. (2013). Qualitative Data Analysis with NVivo (2nd ed.). Sage Publications
25th July 2025 at 3:41 am #16298ParticipantThank you Ben, for sharing your perspective. It’s a relief to hear. I was starting to wonder if I was looking in the wrong places!
Thanks very much for recommending the Jackson & Bazeley text. I happen to have it! It’s what first alerted me to the problem of viral coding. It’s a resource I keep returning to. I just wish there were more like it!
Thank you again for sharing your insights. This exchange has been tremendously helpful.
Sincerely,
Calvin -
This topic was modified 1 year ago by
-
AuthorPosts
- You must be logged in to reply to this topic.
